海草。海草。
Semi-local string comparison: Algorithmic techniques and applications 的翻译,以及一些oi里的例题。
monge, unit-monge, simple unit-monge
现在有一个矩阵$M$,它的下标是整数。定义它的密度矩阵$M^\square$是它的二维差分。这里密度矩阵的下标是整数$+\frac{1}{2}$,称为半奇数,用带帽的变量如$\hat i,\hat j$表示,并记$i^+=i+\frac{1}{2},i^-=i-\frac{1}{2}$,这里$i$也可能是$\hat i$。那么这个二维差分的具体定义就是$M^\square(\hat i,\hat j)=M(\hat i^+,\hat j^-)+M(\hat i^-,\hat j^+)-M(\hat i^-,\hat j^-)-M(\hat i^+,\hat j^+)$。
现在有一个密度矩阵$M$,它的分布矩阵$M^\Sigma$是它的二维前缀和,具体就是$M^\Sigma(i,j)=\sum\limits_{i<\hat i,\hat j<j}M(\hat i,\hat j)$。
如果我们把$(0,0)$这个位置写在左上角,那么这个二维前缀和就是左下方的二维前缀和。看看dengyaotriangle的slide里的图:
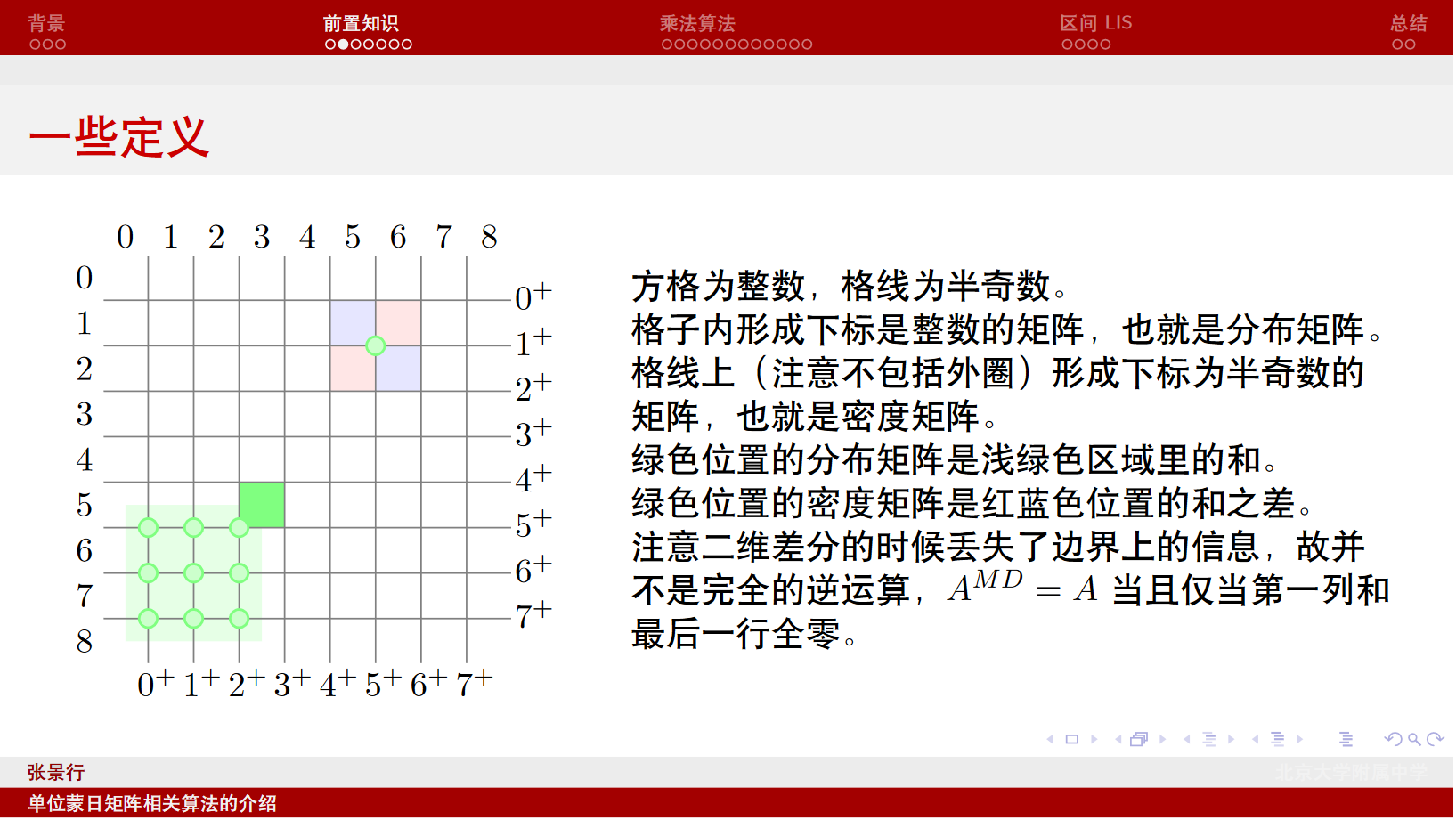
一个下标是整数的矩阵是simple 简单的,当且仅当它的$\square$的$\Sigma$就是它,也就是说它的第一列和最后一行全$0$。
一个矩阵是monge 蒙日的,当且仅当它的$\square$非负。如果非正就叫anti-monge。对于anti-monge矩阵,我们通常考虑的是$(\max,+)$矩乘。
一个矩阵是unit-monge 单位蒙日的,当且仅当它的$\square$是排列矩阵。一个矩阵是subunit-monge 亚单位蒙日的,当且仅当它是一个亚排列矩阵(允许一些行/列没有$1$的排列矩阵)的$\Sigma$。一个矩阵是(sub)unit-anti-monge的,当且仅当它的$\square$是负的(亚)排列矩阵。
以下用$A\times B=C$,或$A^\square\boxdot B^\square=C^\square$表示$(\min,+)$矩阵乘法。
几个简单结论是,monge矩阵,unit-monge矩阵,subunit-monge矩阵,simple矩阵,对乘法都是封闭的。monge矩阵的和还是monge矩阵,simple矩阵的和还是simple矩阵,因为$\square$是线性变换,但(sub)unit-monge显然不满足这个。
monge矩阵乘法可以二维决策单调性做到$O(n^2)$,也就是 石子合并。如果可以$O(1)$查询一个位置,那么monge矩阵乘向量可以smawk做到$O(n)$。用$\square$表示的simple (sub)unit-monge乘法可以做到$O(n\log n)$;不管是否simple,只要(sub)unit-monge,乘向量都可以$O(n)$。如果不simple的话,矩阵乘矩阵就不好做了。
以下对于(sub)unit-monge矩阵$A$,我们会用到记号$P_A=A^\square$。一般用每行那个$1$的列下标表示$P_A$。
行最小值
如果一个矩阵满足各行的最靠右的$\min$位置单调不降,那么它是一个单调矩阵。如果一个矩阵的每个子矩阵都是单调矩阵,那么它是完全单调矩阵。以下我们默认$\min$是最靠右的。
Theorem 任意monge矩阵$A$是完全单调矩阵。
Proof 如果$i_1$行的$\min$在$j_2$列,$i_2$行的$\min$在$j_1$列,满足$i_1<i_2,j_1<j_2$,那么根据monge矩阵的定义,有$A(i_1,j_2)+A(i_2,j_1)\geq A(i_1,j_1)+A(i_2,j_2)$。
如果$A(i_1,j_2)=A(i_1,j_1),A(i_2,j_1)=A(i_2,j_2)$,那么$A(i_2,j_1)$不是$i_2$行的$\min$,$A(i_2,j_2)$才是(它更靠右)。
否则,要么$A(i_1,j_2)>A(i_1,j_1)$,要么$A(i_2,j_1)>A(i_2,j_2)$,与假设矛盾。
接下来我们考虑如何求出每一行的$\min$。每个算法还有两个比较重要的属性:
-
在线/离线: 在线意味着给出前$k$行的$\min$之后,才知道第$k+1$列的值;离线则意味着所有位置都是一开始就已知的。
-
随机访问/指针移动代价较小: 我们认为查询一个位置之后立即查询另一个位置的代价是两个位置间的曼哈顿距离。如果这个代价并不小,认为算法是随机访问的,否则它的指针移动代价较小。比如如果这是个序列dp,信息是莫队可以维护的,较小的指针移动代价就是很有意义的。
好了让我们开始吧。
smawk 死妈文科
离线,指针移动代价$O(n\log n)$,$O(n)$。
现在有个$n\times n$的矩阵,考虑我们取出偶数行,那么它们的$\min$最多只占$\frac{n}{2}$个列,如果我们能删去无用的列(这个操作叫 reduce),就可以递归下去求出这些行的$\min$。然后对于奇数行,直接在上下偶数行的$\min$位置之间枚举即可。
依次处理每一列,维护一个列的栈,我们保持,如果现在栈中有$k$列,那么其中第$i$列不可能成为前$i-1$行的$\min$。
现在考虑新的一列,记它为$k+1$列好了。如果$A(k,k)<A(k,k+1)$,那么我们考虑前$k$行和$k,k+1$两列构成的子矩阵,这个子矩阵中$k$行的$\min$在$k$列,因为它是完全单调的,前$k$行的$\min$都在$k$列,那么$k+1$列在前$k$行都没用了,我们让它进栈。
如果$A(k,k)\geq A(k,k+1)$,那么和上面的分析类似,$k$列在$k$行以后都没用了。而它已经在前$k-1$行没用了,所以它完全没用了,我们把它删掉,让$k\leftarrow k-1$,再次考虑新的这一列。
这里看起来访问挺连续的??好像指针移动代价也是$O(n\log n)$??就是说你一共reduce $\log$层,每层是顺着查这层用到的所有列(因为如果$i$列进栈时在$k$位,那么关于它的查询只有$A(k,i)$了,记下来这个数就不会再查它了),每次查的行要么就是上一次的要么$\pm 1$。然后回溯的时候显然每层都是$O(n)$的。
在线的分治
在线,指针移动代价$O(n\log n)$,复杂度$O(n\log n)$。
对行的下标集合分治。我们在递归到区间$[l,r]$时,假设$0,…,l-1$行的$\min$已经求出,并且$r$行中$0,…,l-1$列的$\min$已经求出。离开这个区间时,我们希望求出$[l,r]$的$\min$。
首先找到中点$m$,找到$m$行在$0,…,l-1$列的$\min$。由于这是一个完全单调矩阵,在任意子矩阵中,$m$行的$\min$都比$r$行的靠左,所以我们可以仅在$l-1,r$两行的$\min$之间枚举。然后递归$[l,m]$。再找到$r$行在$l,…,m$列的$\min$,这里直接枚举也只有$O(r-l)$个位置。然后递归$[m+1,r]$即可。
这里要想指针移动代价$O(n\log n)$,需要开两个查询用的数据结构,分别进行$m$行和$r$行的枚举。
离线的分治
离线,指针移动代价$O(n\log n)$,复杂度$O(n\log n)$。可以适用于单调矩阵(不一定完全单调)。
取中点,直接算出它的$\min$在哪列取得,然后把列从这里也分成两半分别递归。
larsch
在线,随机访问,$O(n)$。
太麻烦了,不会。
所以怎么做乘法??
给定$P_A,P_B$,$A=P_A^\Sigma,B=P_B^\Sigma$是simple unit-monge的,要算$P_C$满足$P_C=P_A\boxdot P_B$,或者说$C=A\times B$。
如果想$O(n\log n)$,先猜可以分治,所以我们分治;但是多少也得有点根据吧,我们看看$C$的定义
\[C(i,j)=\min_k A(i,k)+B(k,j)\]取$m=\lfloor\frac{n}{2}\rfloor$,把$k$分成两部分$k\leq m,k\geq m$,所以我们就把$A$分成了左右两部分$A_{lo},A_{hi}$,$B$分成了上下两部分$B_{lo},B_{hi}$。(这里$m$确实被同时分到两边了,但其实我们是操作$P_A,P_B$,你想象一下,确实应该同时把$m$分到两边。)
对应地把$P_A$分成左右两半$P_{A,lo},P_{A,hi}$(列标号在$[1^+,m^-],[m^+,n^-]$),$B$分成上下两半$P_{B,lo},P_{B,hi}$,定义$P_{C,lo}=P_{A,lo}\boxdot P_{B,lo},P_{C,hi}=P_{A,hi}\boxdot P_{B,hi}$。
Theorem 3.4 若$P_A\boxdot P_B=P_C$,$P_A$的第$\hat k$行全为$0$,则$P_C$的第$\hat k$行也全为$0$。同理,若$P_B$的第$\hat k$列全为$0$,则$P_C$的第$\hat k$列也全为$0$。
Proof 考虑$P_A$的第$\hat k$行全为$0$,等价于$A$的$\hat k^-,\hat k^+$两行是一样的,那么我们乘出来,$C$的这两行肯定也是一样的,所以$P_C$的$\hat k$行也全为$0$。
所以$P_{C,lo},P_{C,hi}$可以递归求出,也就是把$A_{lo},A_{hi}$的全零行和$B_{lo},B_{hi}$的全零列删掉再递归,递归完了再把这些行列插回去。
但是这里$P_{C,lo},P_{C,hi}$其实并不是我们一开始想要的那些项,因为直接把$P_A$分成左右两半,$P_{A,lo}^\Sigma$确实是$A_{lo}$,但$P_{A,hi}^\Sigma$并不是$A_{hi}$,它在$\Sigma$的时候应该考虑$A_{lo}$中的项,但是我们没有这么做。同理$P_{B,lo}^\Sigma$也不是$B_{lo}$。
还好这里我们忽略了的部分的影响是容易考虑的。记$M_{lo}(i,j)=\min\limits_{k\leq m}A(i,k)+B(k,j),M_{hi}=\min\limits_{k\geq m}A(i,k)+B(k,j)$是我们本来想要的东西,那么现在我们要用已经计算出的$P_{C,lo},P_{C,hi}$表示$M_{lo},M_{hi}$。
仔细瞪这个式子:
\[M_{lo}(i,j)=\min_{k\leq m}A_{lo}(i,k)+B_{lo}(k,j)\]刚才说问题出在$B_{lo}$并不是$P_{B,lo}^\Sigma$,要修这个问题,因为$\Sigma$是二维前缀和,有$B_{lo}(i,j)=P_{B,lo}^\Sigma(i,j)+P_{B,hi}^\Sigma(m,j)$。所以
\[\begin{aligned} M_{lo}(i,j)&=\min_{k\leq m}P_{A,lo}^\Sigma(i,k)+P_{B,lo}^\Sigma(k,j)+P_{B,hi}^\Sigma(m,j)\\ &=P_{C,lo}^\Sigma(i,j)+P_{B,hi}^\Sigma(m,j) \end{aligned}\]然后还可以注意到$P_{B,hi}^\Sigma(m,j)=P_{C,hi}^\Sigma(0,j)$,因为
\[P_{C,hi}^\Sigma(0,j)=\min_{k\geq m}P_{A,hi}^\Sigma(0,k)+P_{B,hi}^\Sigma(k,j)\]因为$\Sigma$是左下方的点数,$P_{A,hi}^\Sigma(0,k)$在$k$增加$1$时也增加$1$,$P_{B,hi}$在$k$增加$1$时最多减少$1$,所以$\min$里面的东西随$k$增加是单增的,所以这个$\min$必然在$k=m$处取得,此时$P_{A,hi}=0$,所以就有$P_{B,hi}^\Sigma(m,j)=P_{C,hi}^\Sigma(0,j)$。那么代回上面的式子,我们知道$M_{lo}(i,j)=P_{C,lo}^\Sigma(i,j)+P_{C,hi}^\Sigma(0,j)$。
同理有$M_{hi}(i,j)=P_{C,hi}^\Sigma(i,j)+P_{C,lo}^\Sigma(i,n)$。
现在我们要考虑$P_C^\Sigma(i,j)=\min(M_{lo}(i,j),M_{hi}(i,j))$,那么直接设$\delta(i,j)=M_{lo}(i,j)-M_{hi}(i,j)$,根据$\delta$的符号来判断$\min$取哪边。代入上面算出来的东西,得到
\[\begin{aligned} \delta(i,j)&=P_{C,lo}^\Sigma(i,j)+P_{C,hi}^\Sigma(0,j)-P_{C,hi}^\Sigma(i,j)-P_{C,lo}^\Sigma(i,n)\\ &=(P_{C,hi}^\Sigma(0,j)-P_{C,hi}^\Sigma(i,j))-(P_{C,lo}^\Sigma(i,n)-P_{C,lo}^\Sigma(i,j)) \end{aligned}\]还是从$\Sigma$是左下方点数的角度考虑,我们知道$P_{C,lo}^\Sigma(i,n)-P_{C,lo}^\Sigma(i,j)$就是$P_{C,lo}^\Sigma$中$(i,j)$右下方的点数,$P_{C,hi}^\Sigma(0,j)-P_{C,hi}^\Sigma(i,j)$就是$P_{C,hi}^\Sigma$中$(i,j)$左上方的点数,这个式子就是后者减前者。看一下论文里的图,我们把$P_{C,lo}^\Sigma$中的点标为红的,$P_{C,hi}^\Sigma$标为蓝的,那么$\delta$就是左上方蓝点数减去右下方红点数。
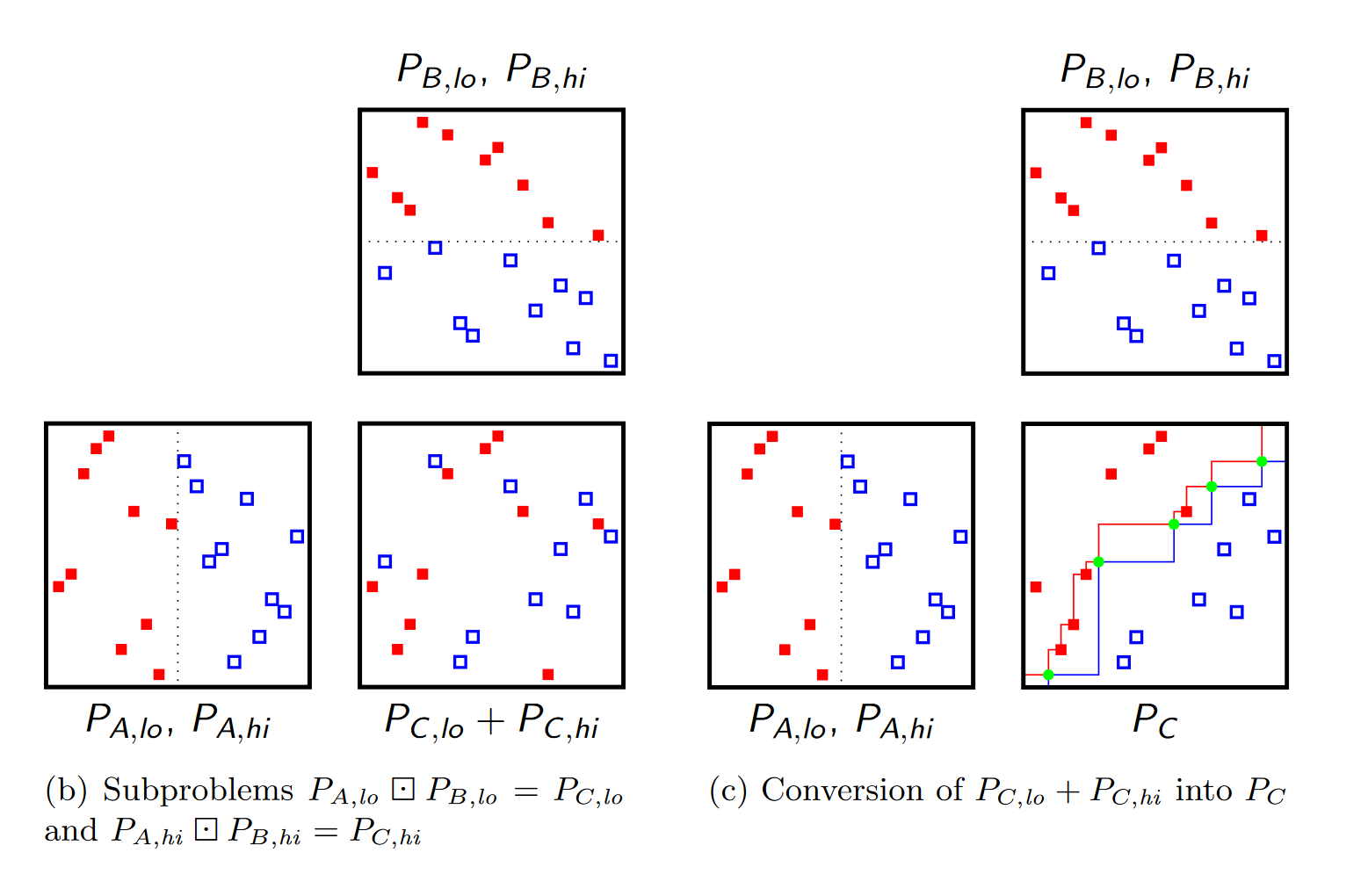
注意到$P_{C,lo}+P_{C,hi}$是一个排列矩阵,因为我们递归之后,把子问题的答案拿上来又插了一堆空行/列,而根据我们生成的子问题,$P_{C,lo}$插的空行/列恰好是$P_{C,hi}$非空的那些,反之亦然。
所以我们知道$\delta$的相邻两项差不超过$1$。
然后显然$\delta(i,j)$关于$i,j$都是单增的,因为左上方蓝点数随$i,j$单增,右下方红点数则单减,差肯定还是单增的。所以我们知道可以画两条单调的分界线把$\delta$分成$<0,=0,>0$的三部分。
双指针求出这两条分界线。只需要每次移动一步,维护$M_{lo},M_{hi}$,根据定义容易做到每次$O(1)$。然后考虑怎么求出$P_C(\hat i,\hat j)$。
如果$\delta(\hat i^+,\hat j^+)\leq 0$,那么根据单调性,$(\hat i^+,\hat j^+),(\hat i^+,\hat j^-),(\hat i^-,\hat j^+),(\hat i^-,\hat j^-)$都$\leq 0$。那么我们都可以取$M_{lo}=P_{C,lo}^\Sigma(i,j)+P_{C,hi}^\Sigma(0,j)$,容易知道此时$P_C(\hat i,\hat j)=P_{C,lo}(\hat i,\hat j)$。
如果$\delta(\hat i^-,\hat j^-)\geq 0$则反过来,$P_C(\hat i,\hat j)=P_{C,hi}(\hat i,\hat j)$。
现在只剩下$\delta(\hat i^+,\hat j^+)>0,\delta(\hat i^-,\hat j^-)<0$的情况。根据单调性和相邻位置最多差$1$,容易知道这四个位置的$\delta$一定是
\[\begin{array}{cc}-1&0\\0&1\end{array}\]这样的。那么两条分界线就交于$(\hat i,\hat j)$这个点。代入$\delta$的定义,四个位置的$C$是
\[\begin{array}{cc}M_{lo}(\hat i^-,\hat j^-)&M_{lo}(\hat i^-,\hat j^+)\\M_{lo}(\hat i^+,\hat j^-)&M_{lo}(\hat i^+,\hat j^+)-1\end{array}\]所以$P_C(\hat i,\hat j)=M_{lo}^\square(\hat i,\hat j)+1=P_{C,lo}(\hat i,\hat j)+1$。由于$P_{C,lo}$是排列矩阵,$P_C$也是排列矩阵,所以$P_C(\hat i,\hat j)$必须是$1$。
那么我们知道$P_C(\hat i,\hat j)=1$当且仅当以下三种情况发生任意一个(事实上也不会发生超过一个):
-
$P_{C,lo}(\hat i,\hat j)=1$,且$(\hat i,\hat j)$不在$=0,>0$分界线的右下方(含分界线本身)。
-
$P_{C,hi}(\hat i,\hat j)=1$,且$(\hat i,\hat j)$不在$<0,=0$分界线的左上方(含分界线本身)。
-
$(\hat i,\hat j)$是两条分界线的公共点。
依此算出$P_C$即可。总复杂度$O(n\log n)$。
dengyaotriangle的板子: https://loj.ac/s/1386385
海草
一个simple unit-monge矩阵对应于一个排列矩阵对吧,这是个半群。
我们断言所有$n-1$个simple unit-monge矩阵,满足对应的排列矩阵只有一个逆序对(也就是说是$1,…,n$交换相邻两项得到的),就是这个半群的生成元。
然后记$A_i$为对应的排列是$1,…,n$交换了$i,i+1$得到的的simple unit-monge矩阵,有如下性质
-
$A_iA_i=A_i$。
-
若$\vert i-j\vert\geq 2$,$A_iA_j=A_jA_i$
-
若$\vert i-j\vert=1$,$A_iA_jA_i=A_jA_iA_j$
同时我们有海草半群,它的每个元素是一个排列矩阵,称为海草,其中如果$i$行$j$列是$1$,称有一根海草从$i$到$j$。海草半群的各生成元$g_i$是交换了$i,i+1$的海草。一个海草$p$乘一个生成元$g_i$,则看$p_i,p_{i+1}$的大小关系,如果$p_i<p_{i+1}$则乘积是$p$交换两者,否则就是$p$,这个法则可以概括为 已经交叉的海草不再次交叉。可以验证海草半群满足上面三条性质。
可以验证海草乘法就是simple unit-monge乘法。
semi-local lcs, the seaweed method
这里前两段写的不是很详细,你应该结合原论文阅读。
我们都知道lcs是一个网格状dag上的最长路,也就是说$(i,j)\stackrel{0}{\rightarrow}(i+1,j),(i,j+1)$,如果$a_i=b_j$则还有一条$(i,j)\stackrel{1}{\rightarrow}(i+1,j+1)$。
现在我们要求边界上任意两个点之间的最长路。可以在左边和右边加满边转化成上边任意一个点到下边任意一个点的最长路。
我们断言答案矩阵$H(i,j)$,也就是上面第$i$个点到下面第$j$个点的最长路,这里定义如果$i>j$则$H(i,j)=j-i$,它是unit-anti-monge的。更进一步的,它满足$H(i,j)=j-i-P^\Sigma(i,j)$,其中$P$是一个排列矩阵。
如下方法可以计算$P$: 从上到下,从左到右扫每个cell,如果这是一个match cell,或者上面和左边的海草已经相交,就不让它们在这个cell交叉,否则让它们交叉。复杂度$O(n^2)$。
最后我们计算$H(i,j)$时,问题就是计算$P^\Sigma(i,j)$,做二维前缀和即可。复杂度$O(n^2)$。
pa20 round 4 A. Tekstówka
两个串$s,t$,每次给各一个区间,求lcs长度。$n,m\leq 3000,q\leq 10^5$,8s。
容易做到$O(n^2\log n+qn)$,因为海草过程中其实求出了一个串的区间和另一个串的所有前缀的lcs(或者在反串上跑就是后缀),在$t$上建线段树(二区间合并结构),把$t$的查询区间拆成一个点左儿子的后缀和右儿子的前缀,枚举$s$这个区间中的一个位置分成两部分,求前半部分和左儿子的后缀的lcs,加上后半部分和右儿子的前缀的lcs,其中最大的就是答案。
但是还可以让$q$上的东西小一点。考虑相当于有个网格图,然后我们要求任意两点的最短路,上面的做法就是分治,考虑分块,把横纵轴都每隔$K$分一块,也就是说每隔$K$画一条横/竖线把平面切成若干个$K\times K$的大方格。对于每条线算出它上面每个点到每个点的最短路,每条线需要一遍海草,总复杂度$O(\frac{n^3}{K})$。查询的时候考虑路径一定会经过起点所在大方格的边界,这个边界长度是$O(K)$的,我们枚举经过了哪个点,然后调用之前算出的最短路即可,总复杂度$O(qK)$。平衡一下,取$K=\Theta(\frac{n^{1.5}}{\sqrt{q}})$,得到$O(n^{1.5}\sqrt{q})$,这里认为$q=O(n^3),q=\Omega(n)$,还是比较合理的。
小问题是两个查询在同一个大方格怎么办,我们再给相距$<K$的两行/两列算一个海草,复杂度$O(n^2K)$,这样就得到$O(n^{2.5}+q\sqrt{n})$。更好的做法是每个大方格用一开始那个分治,预处理总共是$O(n^2\log n)$,查询是$O(qK)$,所以没有增加复杂度。但是其实这在$q=\Omega(n\log^2 n)$时才成立,否则$n^2\log n$是大的,也就是说复杂度其实是$O(n^2\log n+n^{1.5}\sqrt{q})$。
注意到$q$很小的时候,我们是压根没分块的,所以这个分块也没法递归。那就先这样吧。
区间lis
lis其实是和$1,…,n$这个序列的lcs。所以我们就直接这么跑海草就可以$O(n^2)$求所有区间的lis。
要做到$O(n\log^2 n)-O(\log n)$,分治,从中间横着切一刀,算出上下的海草之后用simple unit-monge乘法$O(n\log n)$合并。这里递归的时候需要扔掉没有match cell的列,递归完了再插回来,复杂度就是对的了。
试看看! 例题1.7
ur25 C. 装配序列
一个排列循环无穷次,多次查询前缀严格lis长度。$n\leq 2\times 10^5,q\leq 10^6$。
bonus: 查区间。
显然lis长度不超过$n$,并且循环$n$次则必然到达$n$,那么我们只需要对于每个长度求出最短的前缀即可。
官方题解大概是这样的,考虑我们要求每个前缀的lis,可以从左往右扫用那个二分,也就是维护一个递增序列$b$,如果我们要插入数$x$,找到$b$中$\geq x$的最小的数改成$x$,如果不存在那就把$x$插入$b$的最后。这里$b$其实就是直接做dp时,也就是$dp(i)$表示结尾值$\leq i$的lis长度,那个$dp$数组值改变的位置。
也可以从小往大扫值域,每次和上面一样插入一个序列上的位置,最后得到一个序列$b$,它的长度显然就是整个数组的lis长度。如果要查前缀$k$的答案,找到$b$里面$\leq k$的数的个数即可,因为根据上面和dp的对应关系,它对应于结尾位置$\leq k$的lis长度。
(也就是说其实不管怎么扫,我们都可以查左下2-side矩形的lis
这里如果扫序列,性质是插入的序列的周期为$n$,这其实不太好。如果用这个扫值域的方法,就相当于每次从大到小插入了无穷个值相同,下标为$p+kn$的数(实际上只需要插$n$个,但这不重要),这个要好一些的。
接下来考虑我们插入一个值的时候干了啥。我们归纳证明,对于任意一个数的出现位置$q$,如果$q+kn$在$b$中存在,那么$q+(k-1)n$也存在(当然,除非它$<0$)。这是比较显然的,因为新加入出现在$p$的数的时候,如果原来的$b$满足这个性质,那么对于每个$q$,我们代替的都是它在$b$中存在的那些的一个后缀,也就是说如果某一个没被代替,前面的肯定也不会被代替了。
考虑维护序列$c$,$c_p$表示$p+kn$一共有多少个,那么加入一个新的位于$x$的数时,摘抄一下官方题解
-
初始$c_x=0$。
-
依次访问$(x,n]$中的每一个$i$,如果$c_x < c_i$,那么交换$c_x$和$c_i$。
-
依次访问$[1,x)$中的每一个$i$,如果$c_x < c_i-1$,那么先交换$c_x$和$c_i$,然后$c_x\leftarrow c_x-1,c_i\leftarrow c_i+1$。
-
最后$c_x\leftarrow c_x+1$。
如果你理解了上面所有,这个也不难理解的。然后就注意到最后$c$的总和是$n$,并且这个过程中$c_x$每次改变都是增大,同时,如果增大了$k$次,说明$c$中还有总和为$\Omega(k^2)$的另外$k$个数,那么最多只会有$\sqrt{n}$次找到$i$然后交换,也就是说直接爆力做就只有$O(n\sqrt{n})$次找$i$的操作。这里对$c$的每个值$k$开一个set,维护$c_p=k$的所有$p$,复杂度可以分析到$O(n\sqrt{n})$。最后就可以还原$b$了。
然后考虑怎么海草。
先用海草解释一下这个做法。其实我们就是找到了每条左边来的海草到哪去了,$b$就是这个意思对吧。那么它到哪去了呢??
依次处理每一行。那么这一行最左边来的那根海草肯定会在第一个match cell处往下拐,因为上面来的海草肯定和它没有交过。那么从上面进入这个match cell的海草就会往右延申,它会延伸到哪呢??设这个位置是$p$,这根海草编号是$x$(按起点从左往右编号),那么就要找到$p+1,…,p+n-1$这一段里面下来的海草中第一个编号$<x$的($<x$说明它俩已经相交过了,如果$>x$则说明没相交过,就是这么简单),然后它将取代这根海草的位置,并让这根海草继续往右找。注意到如果$x$是从左边出发的,这根海草的编号$<x$,它就必须也是从左边出发的,而我们不关心左边出发的海草具体是哪一根在这里,反正这个cell出去的两根海草都是左边出发的。如果$x$是上边出发的,那么所有左边出发的海草都$<x$,也就是说遇到了一定发生不交叉,而上边出发的海草具体是哪根我们不太关心,只知道它是上边出发的就够了。因此我们只需维护所有左边出发的海草。这就得到了那个$b$的维护方法。具体一点,现在要插入位于$p$的数,枚举$k=n,n-1,…,1$,每次找到$\geq p+kn$的最小的$b_i$(不存在则进行下个$k$),把它改成$p+(k+1)n$;最后插入一个$p$。这就和前面的东西一样了。
然后考虑bonus: 查任意区间。我们首先说明如何$O(nm)$求一个长$n$的串$s$和另一个长$m$的串$t$重复无穷次,记为$t^\infty$,的每个区间的lcs。考虑$s,t^\infty$的海草也是循环的,就是说如果上面的第$i$个位置连到下面的第$j$个位置,那么上面的第$i+m$个位置就连到下面的第$j+m$个位置。所以我们只需要求出海草交叉情况的一个循环节,然后就可以知道每个位置连到哪。
问题是正要处理的一行每个cell左侧的海草不知道是哪个。
考虑如果$s$的一个字符在$t$中没有出现过,那么把它删掉不影响答案,如此处理后,每行都有至少一个match cell。那么由于match cell处海草必然不交叉,而它上面的海草是已知的,这样就可以从它开始递推这一行的情况。
其实不这么删也行,这一行必然是一条横着的海草转圈,然后每个cell都发生交叉。
然后,要处理任意区间的查询,我们需要知道左上每条海草是从右下哪个地方出去了,dfs一下就可以求出一个数组$d$满足$p_i$位置的海草结束于$p_i+d_{i\bmod{n}}$。那么查询的时候,对于每个$i\bmod{n}$的值考虑其贡献,容易做到单次$O(n)$。
能不能更快一点啊??把查询区间拆成若干整循环节和两边的零散部分,任意一端在零散部分的海草数量可以两侧各一次二维数点求出,整的部分则可以差分之后二维数点。单次$O(\log n)$。
好了接下来看看怎么做这个题。排列-排列问题了,也就是说这个循环节每行有恰好一个match cell,那么我们希望类似于区间lis,也能快速算出这个海草。
全新科技
可以$O(n\log n)$算两个循环节长$n$的无限长海草的乘积!!!
一个循环节长$n$的无限长排列$\tilde{P}$,就是$\tilde{P}(i)=\tilde{P}(i\bmod{n})+\lfloor\frac{i}{n}\rfloor$,然后要求任意两项都不同。
我们首先知道一个循环节长$n$的无限长排列的复合逆,其循环节也长$n$。两个循环节长$n$的无限长排列的复合也是。
我们可以做分解$P=\Gamma\cdot\Phi$,这里点乘是复合,其中$\Phi$的$[0,n)$是一个排列(就是说所有数都在$[0,n)$里),$\Gamma$在$[0,n)$上单增。为了构造这一分解,也就是先应用映射$\Phi$再应用$\Gamma$,我们就给$\tilde{P}$的$[0,n)$排个序,然后给$\Phi$分配每个位置的rank,用$\Gamma$调到目标位置。同时还有分解$P=\Phi\cdot\Gamma$,就是把$P$取逆然后分解,把结果再取逆。
现在要算无限长海草$\tilde{P}\boxdot\tilde{Q}$,我们先做长$3n$的分解$\tilde{P}=\Gamma\Phi,\tilde{Q}=\Phi^\prime\Gamma^\prime$(也就是说$\Gamma$要在$[0,3n)$上单增了),然后取出区间$[0,3n)$,分别记为$P,Q$,用simple unit-monge乘法算$P\boxdot Q$。然后取$Q^\ast$为$P^{-1}\cdot(P\boxdot Q)$的区间$[n,2n)$再复合$\Gamma^\prime$,$\tilde{Q}{\tilde{P}}$为$Q^\ast$为循环节的无限长排列,$\tilde{P}\cdot\tilde{Q}{\tilde{P}}$就是答案。复杂度$O(n\log n)$。